Statistics Prism

Some statistical filters can display results as percentages rather than numbers of occurrences; click the percentage “%” icon to make the change.
Some statistical filters allow results to be sorted in a number of ways. If available, click the icon to the right of the filter title to see its sorting options.
Some statistical filters are linked to a detailed article in Antidote’s guides. Click the icon to consult them.
Counts

Totals and lengths
These filters will give you the number of paragraphs, sentences, words and characters in your text. They also provide the average number of sentences per paragraph, words per sentence and characters per word.
Reading time
These details have been expertly compiled and analyzed to give the average reading time for the entire text. This information can be useful in a number of domains, such as education, advertising and subtitling.
Billing
Some professional writers and translators calculate the fees they charge their clients based on the number of data units (characters, words, phrases, etc.) in the texts they produce. The Billing details are designed to help with this. To rapidly calculate the billing amount, enter the unit cost, the currency and the textual unit you want to use.
Performance

Results
This filter provides information on the number of errors detected per hundred words and the number of errors detected per sentence.
Antidometer
A gauge indicates your relative performance on a scale from Novice (rather poor performance) to Druide (excellent performance).
Error types

Error types separate language detections and group them into classes. Errors and alerts are presented in the form of histograms that indicate the number of detections for each class. Click the name of a class or the corresponding bar and a new histogram appears below it, providing a finer set of detections. When you do so, the corresponding errors are highlighted in the correction panel and are listed under the histograms, letting you concentrate on spelling errors, for example, or focus on the alerts related to capitalization.
- As you apply corrections, the histogram bars gradually change from red to green.
Refining error types from a detection
You can limit the entries displayed in the list of detections to a particular category by selecting an error in the list of detections and opening the context menu (right click). The central section of the context menu provides options to Show only errors of the same category or Show only errors of the same subcategory. For a capitalization error, for example, you can display a list of all errors in the same subcategory, so that you can review and correct them all in a single step.
Languages

The Languages filter shows you what proportions of your text are in English, French and other languages. Click one of the languages in the right-hand panel to highlight the corresponding passages in the text and to display them in the list of detections.
Words

The Words filter displays all the words in the text, ordered by frequency. The ten most frequent words are displayed as a histogram. A drop-down menu under the filter title lets you see only the words belonging to a given syntactic category, e.g. nouns or adjectives. Click a word in the list or in the histogram and all its occurrences are highlighted in the text and displayed in the right-hand list of detections.
Semantic fields

The Semantic fields filter displays the most frequent nouns and proper nouns used in the text. In most cases, each of these belongs to a semantic field, which is a network of other lexically or semantically associated words. Explore these results by clicking your text’s most prominent words.
Etymology

The Etymology filter shows the distribution of words in the text according to their origin. A pie chart with three sections shows the relative proportion of words that derive from the native stock of the English language, were borrowed from other languages, or were created through native word formation. The list of source languages appears at the bottom of the chart, presented in order of frequency, and initially displays the origin of all the words in the text, according to the three sections of the pie chart. When you click one of the sections of the chart, the list changes to display just the origin of the words corresponding to that source:
- for words of native lexical stock, the list includes those languages from which English inherited words at its origin;
- for borrowed words, the list includes all foreign languages, ancient and modern, from which English has borrowed over the centuries;
- for derived words, the list includes second-tier languages, i.e. the original languages used to create new English words, as well as word origins that are not languages as such, like proper names, onomatopoeic forms and interjections.
In all cases, clicking a particular word origin in the list highlights all words of that origin in the text—for example, highlight all the words derived from Old French by clicking Old French in the results list.
- For more information on the origins of English words, click the icon in the upper right corner of the results panel.
- For more information on the origin of a particular word, click the title of the language/origin under which the word is displayed in the results list, then click the guides icon in the tool bar or in the context menu (right click) to display the relevant article.
Tenses
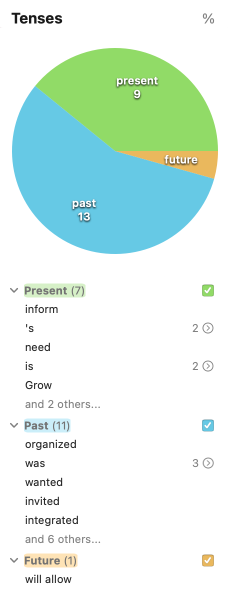
The Tenses filters show the number and distribution of verb tenses used in your text. Click one of the sections of the pie chart to highlight all occurrences of that verb tense in the correction panel.
Categories

These filters show the number and distribution of syntactic categories in your text. Click one of the sections of the pie chart to highlight all occurrences of words that belong to that category in the correction panel. By default, only the major syntactic categories are displayed. To display all categories, click Other categories. Click Fewer categories to revert the chart to its original state.